
Federated Web Rings and Link Sharing
Historically I have struggled to maintain a decent list of bookmarks in any browser - for some reason putting them in the browser just means that I immediately forget that they exist at all, making the whole exercise rather pointless. So on the previous iteration of my website, I instead managed a list of links to resources that I commonly enough used, but did so infrequently enough that I would forget they existed before needing them again.
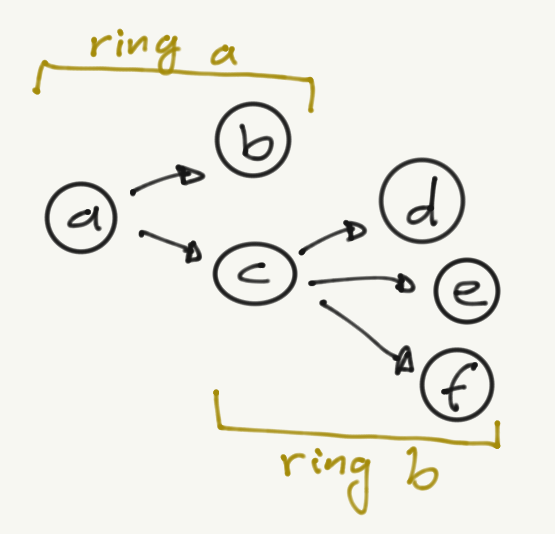
This works well enough for me and could act as a bit of a directory for others, but I thought “wouldn’t it be neat if we could all work on a big curated list of links we individually found interesting, then have them automatically joined together for indexing and searching?” - and yes slightly younger me, it would indeed. The mechanics for this to work are pretty simple too; if we know where a ‘far’ site keeps its list, and we agree on a format, we can wander that list as well, then; using that list we can wander the new links, and so forth until we have a complete list, or get bored following links.
This results in a kind of ‘federated link directory’ with hand picked links that folks have discovered over time, and from wherever you enter the graph from, you get only URLs that are federated from another peer, and so get slightly different resultant list views. With the addition of a few ‘core’ peers acting as master-ish lists, you can also get a pretty complete view of the whole network.
So I set out to implement this on my site here, so starting with a JSON object, where each key is a link at the top level; we end up with the simplest implementation like so:
{
"https://example.co.uk": {}
}The file should exist at /webgraph.json (by convention) but can be overridden by setting the webgraph property for a link entry.
As each link is an object, we can then add optional metadata to each one, allowing us to refine the entry, so a more complex example for a single site might look like this:
{
"https://example.com": {
"title": "An example website",
"tags": [ "example", "web", "testing" ],
"description": "This is just an example website, used mostly for testing",
"webgraph": "my-cool-webgraph.json"
}
}The individual properties and their types are described below.
The entries in this object can then be used in a couple of ways:
- The ‘local’ site can use this to generate a links page, to just have a public set of bookmarks without spidering at all; this is the simplest case.
- Any WebGraph spider that gets linked to the JSON can now add the links to its directory, and also follow them if they’re defined as having additional graph files.
- A WebGraph spider can use the data here to build a more interactive, searchable list of links for a bigger directory.
I’ve implemented a proof-of-concept spider over at the WebGraph page on this site which will attempt to check the graph periodically and update a simple directory list of links. In the future I’d like to expand this to include search functions, but for now it just presents everything in a flat list.
Optional Properties
"webgraph": "/webgraph.json" A site-local path; the WebGraph URL. If omitted this site is not wandered to build the link graph.
Its worth noting that this does not have to be a bare .json file, but could just as easily be any other valid URL that returns a JSON object. For smaller sites I envisage that the authors would maintain their own .json file and just serve this, parsing it to generate their own link lists on their local site, but for larger indexes this could easily be pulled from a database, or autogenerated from crawling internal pages for external links, for example.
I realise that this could theoretically become extremely large, especially if there are any consolidating sites that rebuild their webgraph data as they spider, however I’m leaving this problem for ‘future John’ for now, as I’d like to see if this experiment works at all first. The graph could fairly easily be paginated however, with the addition of some kind of GET arg like ?p=2 for ‘page 2’ for example, although this would also require that the API exposed had some way of defining an upper limit for how many pages it could serve (unless we just pull until the request fails, but that feels bad to me).
"title": "The Homepage of Cool Mc'Dude" A string. The title string, otherwise the URL should be used in place of a title.
I might scrape this from the link URL later if this property is missing, but this will override that behaviour in any case. Note that right now the spider on this site will use the lexographically-ordered first-found entry for a given site, and drop any other subsequent duplicates. In the future I expect I’ll collect them all then pick the ‘best’ (for various definitions of best) value for these to display, but this behaviour is entirely up to the spider. If you don’t like the behaviour seen here, then do feel free to implement your spider however you like!
"tags": [ "friends", "cool", "dude" ] A flat string array. This is just a simple list of free-form tags, which are later collated by the spider to build tagged link groups.
This can be used in any number of ways to group links together; perhaps by country, language or region (indeed, many of my own so far have ISO country code tags), or perhaps by topic or ‘#hashtag’ maybe? I leave the specific uses of the tags for the network itself to resolve, and that they merely act as a loose way to group links together.
"description": "Some cool person's site!" A free-form string, providing a description for this URL. My spider on this site will attempt to display this if it is present, although it will filter the content if it is excessively long (actual max length to be defined) or contains bad characters (already filtered for all common ones).
Properties Subject to Change
"feed": "/feed.xml" A site-local path. This can be an rss feed, or sitemap.xml or equivalent schema, wandered to populate sub-page lists if present, or skipped if omitted.
I’m a little on the fence about this one, and it may well change to individual typed definitions, with a distinct sitemap and rss options for those types. Perhaps I should include this as sub-property of the larger object for a site, maybe under a meta key, to prevent namespace pollution.
Feel free to tell me I’m wrong in the comments below.
Comments
Join the discussion this post on Mastodon
Comments and content are copyright their authors below.
(Comments are updated when the site rebuilds, so may take up to 24 hours to appear!)